

















高效能運算(HPC)及雲端服務是支援人工智慧(AI)發展的重要技術,對此,NVIDIA透過採用Transformer引擎及Hopper架構,強化A100 GPU效能,用以運算大型AI模型。同時NVIDIA為Rescale雲端平台提供AI軟體,為其高效能運算即服務(HPC-as-a-service)產品帶來新功能,同時加速Rescale運算推薦引擎(Rescale Compute Recommendation Engine)的執行速度。
A100 GPU運算效能加倍
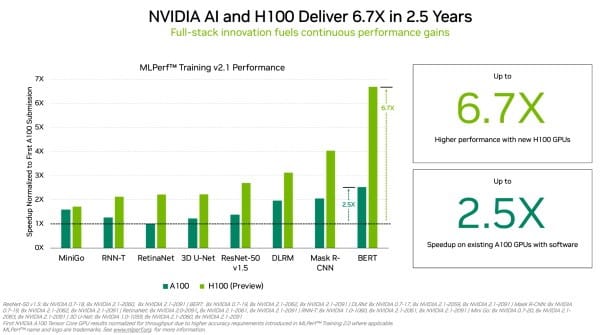
日前NVIDIA宣布在MLPerf相關基準測試中,NVIDIA A100 Tensor核心GPU提高了2021年在HPC立下的標準。H100 GPU採用Hopper架構,提高了 MLPerf 訓練中單一加速器的效能標準,在首次將H100 GPU用於 MLPerf 訓練時,表現相較前一代 GPU高6.7倍的效能(圖1)。
加上以同樣的比較基礎來看,由於軟體的進步,目前A100 GPU的運算能力又高出2.5倍。效能大幅提升的原因之一是Transformer引擎,Hopper架構在訓練用於自然語言處理的BERT模型時有良好的表現。BERT是MLPerf AI模型中規模較大、對處理效能要求較為嚴苛的模型之一。
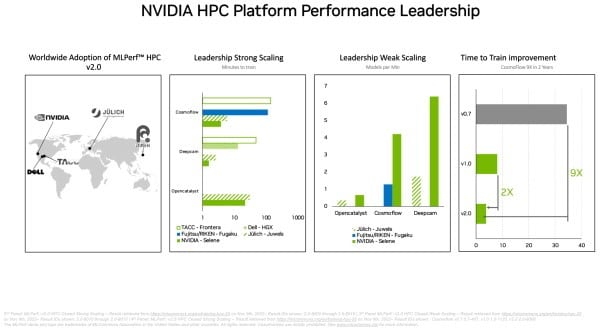
在獨立的MLPerf HPC基準測試,在超級電腦上運行嚴苛的科學作業負載時,A100 GPU在 AI 訓練模型所有測試項目中的表現良好。例如A100 GPU在 CosmoFlow測試中訓練AI模型,比兩年前第一輪MLPerf HPC測試的最佳結果還快9倍。在同樣的作業負載中,A100的每個晶片處理量亦比其他產品高66倍。HPC基準是用於天體物理學、天氣預測及分子動力學的工作訓練模型,藥物開發等許多技術領域同樣採用AI來推動科學發展(圖2)。
在企業 AI訓練基準測試方面,包括Microsoft Azure雲端服務在內的11個公司使用NVIDIA A100、A30 和 A40 GPU提交測試結果。華碩(ASUS)、戴爾科技、富士通(Fujitsu)、技嘉(GIGABYTE)、慧與科技(Hewlett Packard Enterprise)、聯想(Lenovo)及美超微(Supermicro)等系統製造商,共使用九套 NVIDIA 認證系統提交測試結果。
在最新一輪的測試中,至少有三家公司與NVIDIA一樣提交所有MLPerf訓練作業負載的八項測試結果。真實環境中的應用程式往往需要一套涵蓋多種AI模型的方案,因此通用性更顯重要。NVIDIA的合作夥伴認為客戶會使用MLPerf工具來評估AI平台和供應商,因此參與MLPerf基準測試。
AI軟體強化Rescale雲端平台服務
工業科學運算領域容易在資料處理效能方面卡關,因為若要解決看似棘手的難題需要用到大量的高效能運算資源,無論是開發新能源、創造新的運輸模式,或是解決提高營運效率及改善客戶支援等重大問題皆如此。包含伊萊克斯(Electrolux)、電裝(Denso)、三星(Samsung) 和維珍軌道(Virgin Orbit)等企業皆捨棄架構、設計和打造更多的超級電腦,轉而採用Rescale雲端平台,期望以節能的方式擴大加速運算的規模並加速創新。
Rescale將採用NVIDIA AI軟體產品組合,以滿足工業科學領域對雲端AI不斷增加的運算需求。NVIDIA AI將為Rescale的HPC-as-a-service產品帶來新功能,包括各產業廠商使用的模擬與工程設計軟體。NVIDIA協助加速甫推出的Rescale運算推薦引擎的執行速度,客戶可以使用該引擎找出正確的基礎設施選項,最佳化部署的成本與加速落實各項目標。
NVIDIA與Rescale宣布致力於將NVIDIA AI Enterprise導入Rescale,再加入以NVIDIA支援的AI工作流程和處理引擎,擴大雲端平台的產品選擇。待正式推出後,客戶便能在NVIDIA的支援下,於各大雲端環境中開發AI應用程式。企業可以利用NVIDIA AI平台開發預測模型,藉由機器視覺、路線和供應鏈最佳化、機器人模擬等應用程式,互補並擴充工業高效能運算的研發工作。





